

Understanding the scale:
- 100+ Million downloads
- 30+ Language support
- 20+ Billion matches
- 1.8 billion swipes every day (left swipe, right swipe, super like)
- 50+ million members
Our design needs to be scalable to support 50+ million userbases. Tinder supports 30+ languages which means users are spread across around the world. Hence this can’t be a simple application hosted in a single continent as such, it has to be well distributed to give the optimal performance to all the users across the globe.
Tinder is completely hosted on AWS cloud. It doesn't have any web application but IOS and Andriod. Tinder uses AWS amplify to build and test mobile applications, MongoDB for DB, and Redis for caching and in-memory database.
Features:
Features set that we will be focusing on are as follows:
- Login using OAuth (FB)
- Swipes (Left, Right)
- Matching
- chat
- push notification
- super likes
Before deep-diving into how the recommendation engine works i.e when a person logs into the Tinder, how is one able to see several hundreds/thounsands of profile. To begin with let’s talk about the features of the recommendation algorithm that tinder is using.
- Active usage: Tinder’s main purpose to make people meet, to establish meaningful relationships, so if one party is not active it doesn't add to the core objective of tinder.Therefore it is important to know How actively a person is using the application.
- Collect tags: When a person does oAuth using FB, Tinder collects lots of meaningful information like location, age, distance, gender preference, places visit, likes, dislikes, and many more. It also extracts lots of information from pictures and what we write in our profile for a better match.
- Group userbase: When a person login/sign-in to tinder, he/she got assigned some random score from tinder, and based on these score one falls in some bucket lets say we have a bucket from 1–10, this grouping helps in matching people i.e people from bucket 1 tends to prefer more/match with people in bucket 1,2 and 3. This is basically for a high chance of matching based on your likes and those people who have some taste as of yours.
- Your pickiness/Bad actors: If one is doing too much of right swipe, it’s bad, you may not be shown recommendation of other people. Also if one is not doing left swipe at all, still one is not gonna shown in the recommendation of others, as they are not contributing towards the objective of this dating application.
- Do you reply? : How willingly a person is replying after a match.
- Progressive taxation: If one is getting too much of matches/attention, to make it fair for others, Tinder normalizes this by not showing that profile to many other users. At the same time, if someone is not getting much attention, tinder starts bringing that profile to other users.
Recommendation Engine properties:
This recommendation engine brings up the profile of other people based on the above-mentioned points. Below are the properties of the recommendation engine. (Referening Recommendation engine as RE)
- Low latency: When a person logs in to the application,we need to load profiles/potential matches profiles real quickly. Therefore,our RE needs to have low latency.
- Not realtime: It’s okay if it’s not realtime i.e if someone newly joins tinder it’s okay if it take a min to show this person's profile on our account.
- Easy to shard/distribute: Since we have tons of profiles from across the globe, this recommendation engine should be able to shard the data as we can’t keep it in one system.
- Full-text search: we need to search thorugh the whole profile of an individual, to provide better recommendations
- HTTP interface: or web socket to get the data and send it to the application.
- Structure data: XML/JSON
What Tinder uses for storing and searching through data is “Elastic search” which is basically a search system.


Elasticsearch is able to achieve fast search responses because, instead of searching the text directly, it searches an index instead. Additionally, it supports full-text search which is completely based on documents instead of tables or schemas.
Data are clustered for a given location. Tinder basically wants people to meet. If I am a user from location X, India, I will obviously like to get a match with someone who is from location X + 50km. Even in the application, there’s a setting to modify this number(+50km) to some other number i.e what should be the range of my potential matches?
How to shard data to make elastic search queries faster?
Shard the data by geographical location.!!
How do we shard the data on the basis of geographical location?

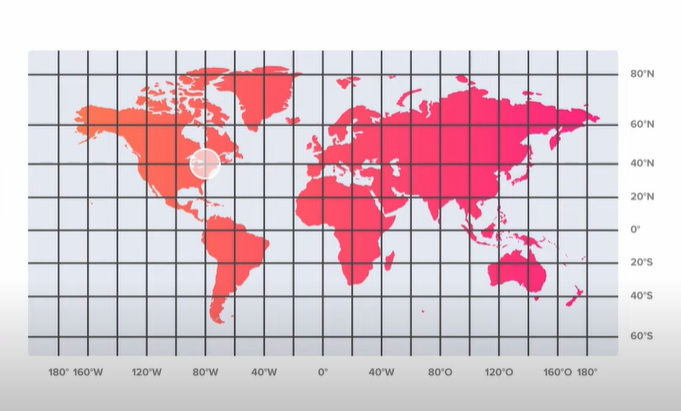
Consider the above map. We here are dividing the whole world map into small boxes. We can place each server in these boxes to serve any requests originating from these boxes (i.e particular lat-log within that box) will get served by servers in that location ( Ideally these servers can be at any physical location, but for each of these boxes/cells, there is one designated server). As we can see these boxes are spread across the ocean as well where we obviously dont need to put any servers as it would be a waste( No one lives there). Now there are certain boxes where the population is high, there one server won't be able to serve all the requests.
So how can we divide the world into boxes and distribute the load across our servers?
The size of the boxes in different areas is determined by Unique user count, active user count and query count from these regions.
some or all of these points decides the size of the box/cell.
We have to find a balance score on the basis of the above factors to get the optimal size of the box/cell (for which we use Google s2 library to save these cells) and see the latency/performance for that area.

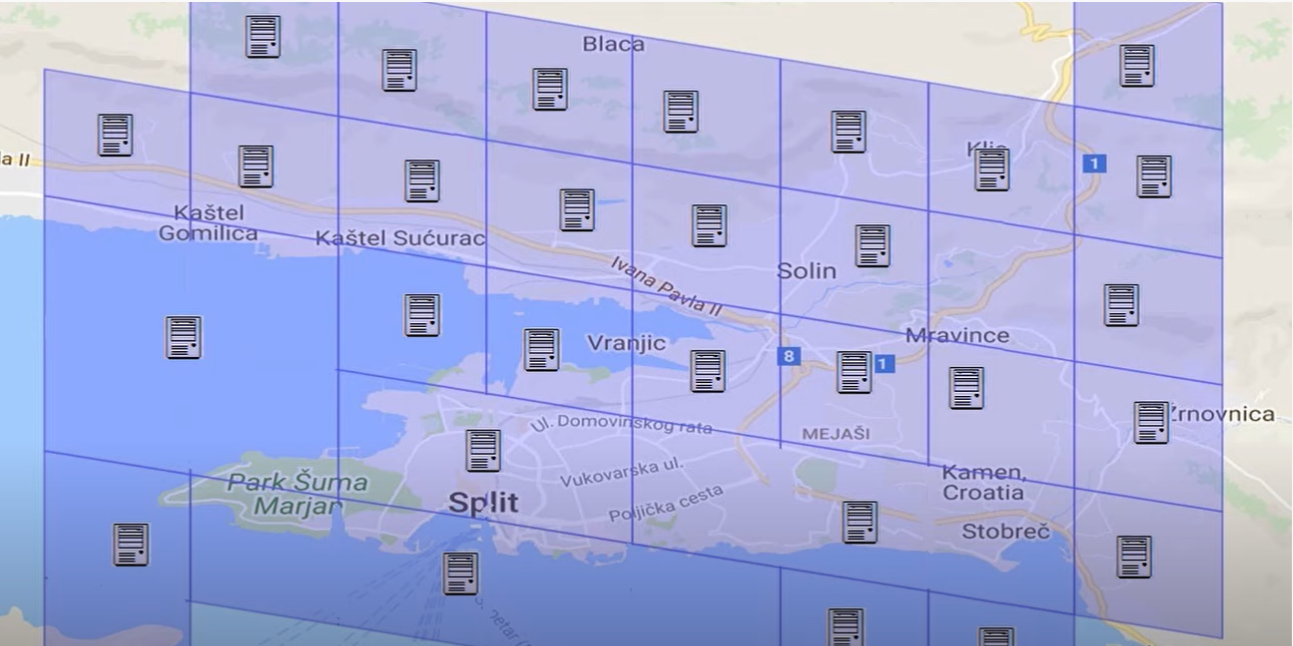
Whenever a person wants to open tinder, his phone makes a query to a system .This system is basically a mapper system which based on the lat-log of the user gives information to the application/user that all of your data is stored on which server.This server is the server where users information lies as well as this can be the server where user’s potential matches lies. As mentioned before servers can be in any physcial location, but all the data belongs to that particular cell will reside on that one server.
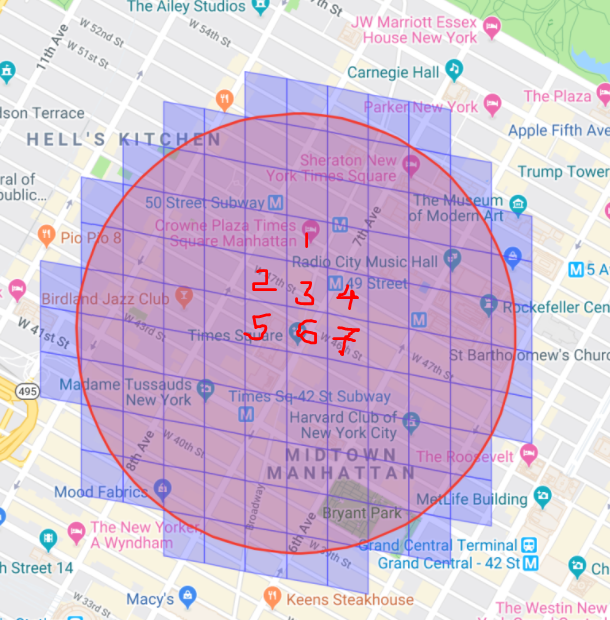
Now consider this above map, let’s concentrate on cells 1,2,3,4,5,6 and 7. Information belongs to there cells will be store on ser1,ser2,ser3,ser4,ser5,ser6 and ser7.
So I am a Tinder user residing at cell 3 and has set my range as 100km i.e I want to know all my potential mathes within 100km range from my location. My information resides at server-3 and my potentials information recides in this radius of 100 km which includes all these cells from cell 1 to cell 7. Requests will go on to all the servers i.e ser1 to ser7 and gather the recommendations.
That’s how recommendation works on Geosharding.
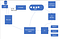
As we can see in the above image, as soon as the new user sign-in to the tinder app using FB oAuth, his profile details go to the ES feeder service using HTTP/WebSocket. One copy will be store in DB also (by user creation service which adds it to the persistence) and another copy to elastic search as we need a fast search for the recommendation. Kafka consumes these messages as need to index these data asynchronously. ES workers pick up the message and send it to the location to the cell mapper which uses the s2 library and has lat-long information. It returns what shard this information will write in to. ES Worker then tells into ES and info gets written to that particular shard using ES API.
User information is now saved in Elastic search and he is now ready to do left/right swipe.He then makes a call to the recommendation engine and which in turn call to the location to cell mapper again with lat log and it returns multiple shard/s to which it makes parallel calls to Shard/s and gets couples of documents/profile and send this info to the mobile using HTTP/web socket. Now all the profiles are being rendered to the user and he’s ready for left/right swipe.
2) MATCHMAKING:
Let’s consider that there are two profiles A and B
There can be three situations possible:
1. A and B right-swipe each other at the same time to one other.
2. A does right swipe to B and B doesn't.
3. B does right swipe A and A doesn’t until now.
There are millions of matches happening every day. We can have one matching service one cell or We can group couple of cells togther with one matchmaking service. so there will be couple of matchmaking service up and running (there will be lots of queries for recommadation queries so to balance out queries per location) and each mathcmaking service belongs to couple of cells instead of just one cell as was in case of geosharding.Match also works in the same manner. Match won’t happen between countries, It will happen in the cell where a profile is recommended to a user.
For e.g if we recommened 100 profiles to user, chances are there will be on an avg 20/30 swipes, so we dont need one matchmaking service per cell.

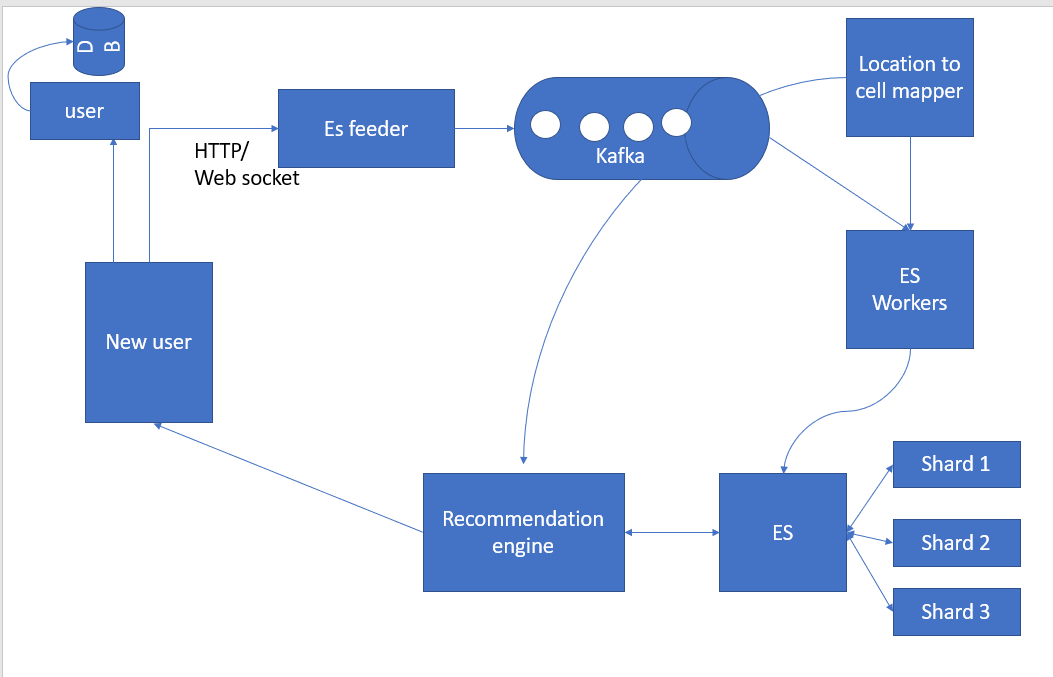
As depicted in above image, whenever a user do the right swipe, a message send to the matchmaking service preferably by web socket, where the location manager determines to which shard or matchmaking service this message will go, and redirects message to the gateway, which connects to Kafka. The message is now in the queue. Depending on the number of shards we have got as a result form location manager serverice, there will be one or many matchmaking service to which this information will be broadcasted to. Information captured here is who is right shipping whom, location, and other metadata. There can be parallel workers which keep reading message coming from the Kafka queue.
If A happens to right swipe B, then an entry like “A_B” enters into Redis and leaves it as it is. Now when B right swipe A, then again the same process happens, match worker picks the message and checks in Redis weather “A has ever right-swiped B’ i.e we will definitely find key “A_B” and check for the metadata, which means a match has happened and message will enter in the matched queue which gets picked by match notification and through web socket sends it to both A and B saying “It’s a match”.


If for some reason, A has never right swiped B then what will happen? Then just a record “B_A” will enter into Redis and that’s it. when A right swipe back B then before adding the key it will check for the key.
User login + profile for tinder
We already know the ES stores user info,that is already geoshards.why don't we just have one more API expose from es to provide specific user profile info. The only optimization we can do is to have one more layer of cache in form of ES so that we can have better performance. We can store user-related info in a database as well. We can have RDBMS as we won’t have too many of records also it needs to be geoshared. so if geoshared is taken care of, we can have our details in RDBMS. We can also link order table info with the user table. We can also opt for NoSQL as it’s auto sharding, it automatically scales itself. We can go with MongoDB as well as it provides ACID property and sharding by geo.
How to enable user login? A user can log in using FB oAuth by registering our application in FB API.We can get lots of information like places user has ever visited, likes, dislikes, close friends, etc, as Tinder wants to build relationship app, we need to have legitimate profile and decide should we really need to show this profile to other or not.We don't need to implement sessions in here. Since we are trying to write an app in native android or apple SDK,we don't need to have sessions all we need to maintain authentication token.
Content moderation:
Constantly keeping eye on content. For e.g : one can use celeb pictures or write bad status what if everyone is doing this and tinder is not suppressing this, then engagement goes down. Therefore, moderating content is important.
How do we achieve this?
Every action performed by an user is an event, like user updates the picture, updates the status or does a left/right swipe, these event needs to get pushed in event sink and get stored in persistence. There we need to use some technology like map-reduce or Kafka streams or spark to get the useful info from event run ML algo on recent changes to check if the profile pic is user’s profile pic or is copied/using celeb pic, No swipe, only right swipe. We need to detect all these event, we also need to keep an eye on the rate at which the user is doing the right swipe, whether he’s really reading it, or blindly doing the right swipe.
MONITORING:
Without monitoring, we don’t know what’s happening with our system and also to check system performance and SLA compliance. One such tool is Prometheus which provides features like altering, write queries, and also stores time series data.

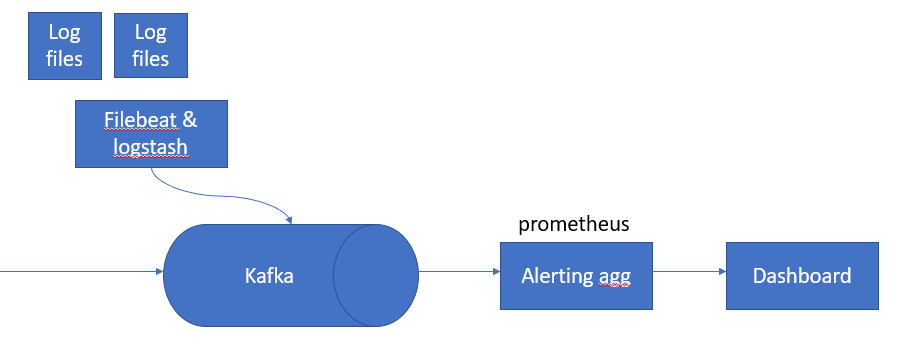
It can be used to monitor the application ,collect logs and monitor system’s performance. All the user events get forwarded to Kafka which then gets read by Prometheus where we write aggregators to identify latency in any geoshard(for eg: Suddenly our app will get trending by one tweet and lots of users start login in, traffic increase in that geo shard — ASG). All these informations gets captured in the dashboard.
Kafka is like an event sink where we can push any kind of data which internally has lots of topics and we can read it at Prometheus. The same system can leverage to consume other logs which generated by other application and these files get read by filebeat or logstash and get forwards to Kafka and can use the same system to track system performance.
This is all about monitoring our application.
So far we have discussed several features of Tinder or the same set of features that will also be available for any other tinder-like dating application. We have discussed about geosharding, matches, swipes, content moderation, and many more.
In the few upcoming blogs we will see chats (Whatsapp-like chatting application), how to store images (Instagram/like application), and many more.
Stay tuned!!
Comments
Post a Comment